The prosodic, spectral, and voice quality parameters, are valid markers in assessing the severity of manic and depressive symptoms. The accuracy of the predictive generalized mixed-effect model is 70.9%-71.4%. Significant differences in the effect sizes and directions are observed between female and male subgroups. The greater the severity of mania in males, the louder (β = 1.6) and higher the tone of voice (β = 0.71), more clearly (β = 1.35), and more sharply they speak (β = 0.95), and their conversations are longer (β = 1.64). For females, the observations are either exactly the opposite-the greater the severity of mania, the quieter (β = -0.27) and lower the tone of voice (β = -0.21) and less clearly (β = -0.25) they speak - or no correlations are found (length of speech). On the other hand, the greater the severity of bipolar depression in males, the quieter (β = -1.07) and less clearly they speak (β = -1.00). In females, no distinct correlations between the severity of depressive symptoms and the change in voice parameters are found.
READ MORE

BIPOLAR software package consists of two main modules: (1) preprocessing of raw signal from sensors; (2) semi-supervised learning for mental state prediction. The second one has just been released. We are now finalising the integration of these two to deliver
the final integrated version of our software for uncertainty-aware semi-supervised computations.
Check out our repo. Start with ssfclust vignette
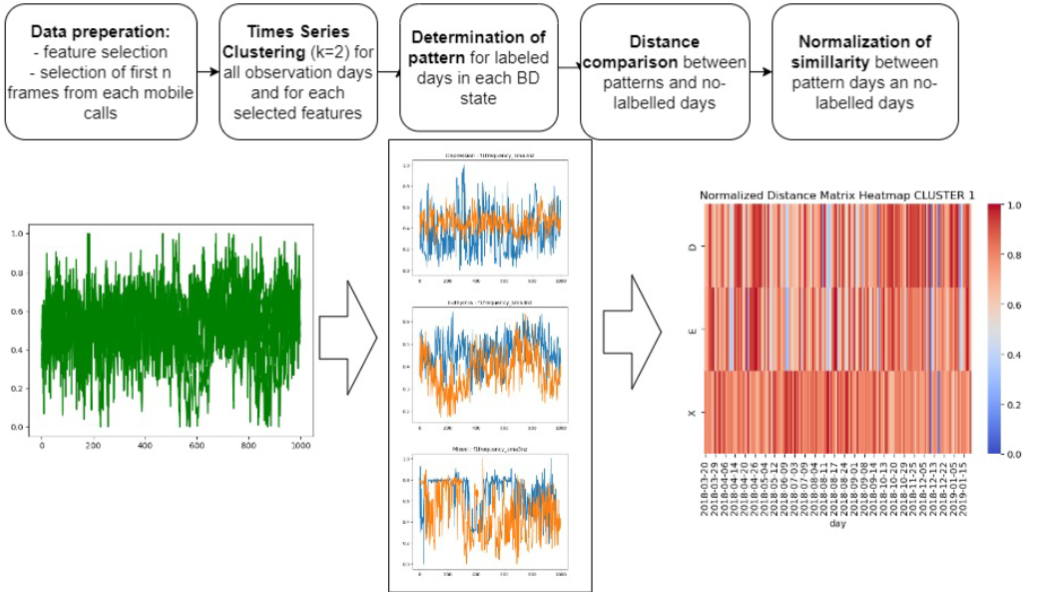
Today our PI Kasia Kaczmarek-Majer and PHD researcher Olga Kamińska participated in POLFUZZ session on Uncertainty and Imprecision in Decision Making in Warsaw. Olga presented most recent results on the assessment of similarity of sensor data streams using unsupervised learning: use case in mental health monitoring. These experimental results are promising to reveal new trends in data and confirm the complex nature of the considered applied problem. Already at the initial stage, we are able to indicate characteristics for selected states. In further work, the distance metrics will be expanded.

Yesterday PHD researcher Olga Kamińska presented our latest paper on uncertainty-aware feature selection during XAI workshop held within the Artificial Intelligence in Medicine Conference in Slovenia (#AIME). It is one of the best international conferences focused on applied artificial intelligence for the medical sector https://lnkd.in/dut9yVPG. We presented the cost-constrained method for feature selection applied in the mental health monitoring context. We are adding a cost factor parameter that controls the trade-off between feature importance and its cost. The experiments were performed on a large medical database collected from patients with bipolar disorder during their daily mobile calls. The results indicate that the cost-constrained method allows to achieve better results. It was a joint work with Tomasz Klonecki from Institue of Computer Science PAS. Thank you Tomasz for fruitful cooperation about this topic.
READ MORE
The last three days were filled with engaging presentations and inspiring discussions.
Thank you Lodz University of Technology and Polish Alliance for the Development of Artificial Intelligence (https://pp-rai.pl/) for organizing the 4th Polish Conference on Artificial Intelligence.

Another release of the BIOPOLAR package is here!
We have added several functions for data preprocessing and wise combination of sensor and psychitric data.

We wish you all the best for the coming year.

Today Olga was presenting our latest paper
„PLENARY: Explaining black-box models in natural language through fuzzy linguistic summaries”
READ PLENARY
on Women in Machine Learning workshops #WiML2022 during NeurIPS Conference 2022 #neurips2022.
Our poster met with great interest!
Olga, congratulations!!!

Today Olga presented at FEDCSIS2022 our recent work investigating the impact of clustering of unlabeled data on
classification.
Currently, it is possible to collect a large amount of data from sensors. At the same time, data are often only partially labeled. For example, in the context of smartphone-based monitoring of mental state, there are much more data collected from smartphones than those collected from psychiatrists about the mental state. The approach presented in this paper is designed to examine if unlabeled data can improve the accuracy of classification tasks in the considered case study of classifying a patient's state.
First, unlabeled data are represented by clusters membership through Fuzzy C-means algorithm which corresponds to the uncertainty of the patient's condition in this disease. Secondly, the classification is performed using two well-known algorithms, Random Forest and SVM. The obtained results indicate a minimal improvement in the quality of classification thanks to the use of membership in clusters. These results are promising due to both, the accuracy and interpretability.

BIPOLAR will be evaluated not only for acoustic datasets but also for data collected from locomotor sensors.
In the recent weeks we have been collecting requirements from our colleagues from the team of Prof. Svetlozar Haralanov from University Hospital for Neurology and Psychiatry "St. Naum" in Sofia, Bulgaria.
Olga is now finalising the requimenment analysis when visiting the hospital in Sofia.
The aim of the second pilot will be to predict depression with locomotor data.
It consists of two main components: learning model for prediction and generating dashboard.

We are very excited to share this news!
We got a best paper award at the IEEE International Conference on Fuzzy Systems for our research about confidence path regularization for handling label uncertainty in semi-supervised learning: use case in bipolar disorder monitoring which is part our #BIPOLAR project.
Kamil, congratulations!!!
We take this opportunity to thank Gabriella Casalino and Giovanna Castellano for great collaboration.
We also thank the IEEE Computational Intelligence Society for appreciating our work.
Greetings from Padua!

Today Kamil presented at the World Congress on Computational Intelligence our recent work on handling label uncertainty via confidence path regularization.
Semi-supervised learning has gained great interest because of its ability to combine unlabeled data with -- potentially few -- labeled observations in a training process.
However, in some application contexts, one can question whether all available labels are equally valid.
For example, in the context of bipolar disorder (BD) remote monitoring, a common practice is to extrapolate the psychiatrist’s assessment onto some fixed time window surrounding the visit, the so-called ground truth period.
In consequence, all data from this period are labeled with the same category.
Such an approach may potentially result in misguided supervision affecting the model's performance.
In this paper, we consider the problem of label uncertainty, assuming that the labels are crisp, but they may be assigned to particular observations with varying confidence.
We propose a novel method called Confidence Path Regularization (CPR) that
incorporates this uncertainty
into the fuzzy c-means semi-supervised learning. The proposed CPR approach is a novel method for automatic, data-driven handling of label uncertainty.

Today Kasia presented at the World Congress on Computational Intelligence our recent work on experimental evaluation of the accuracy of an ensemble of fuzzy
methods for classification of episodes in bipolar disorder.
Considering the possibility of continuous speech data collection via a smartphone app, voice analysis has great potential for monitoring mental states.
Nevertheless, there is still a need to select the most effective validation approaches for solving the task of predicting the mental state.
The sensitive point is the vicinity of the threshold of transition to a disease state. It should be noted that due to minor differences inherent in such cases, it seems intuitive to use fuzzy numbers to determine the patient’s assessment. Experiments confirmed also that the ranking of methods depends on the choice of the training set and evaluation metric.

Today we participated in the 1st Workshop on Online Learning from Uncertain Data Streams in Padua, Italy.
BIPOLAR software package will consist of two main modules: (1) preprocessing of raw signal from sensors; (2) uncertainty-aware semi-supervised learning for mental state prediction. The first one will be delivered as first. Stay tuned!
We are looking for a Lead Software Engineer to join BIPOLAR team !

In the last 3 days, we participated in the PP-RAI Conference (3rd Polish Conference on Artificial Intelligence)
Our PI presented evolving linguistic summarization approach supported with possibilistic aggregation.

Today there was the kick off review meeting of the International Advisory Board.
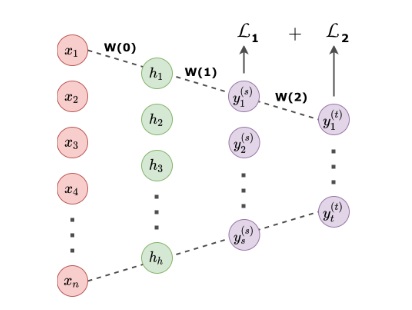
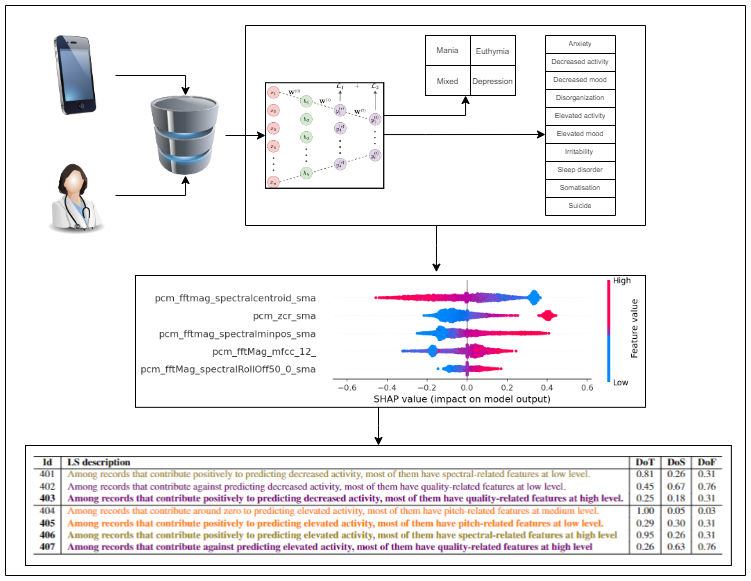
We have just submitted a paper to Information Sciences introducing PLENARY - a framework for explaining black-box models in natural language through fuzzy linguistic summaries.
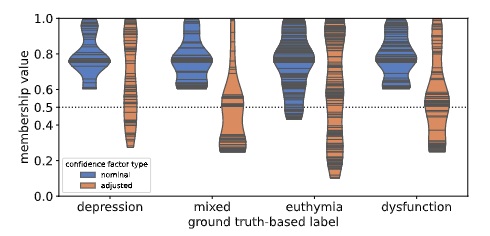
We have just submitted a paper to World Congress on Computational Intelligence introducing Confidence Path Regularization for handling label uncertainty in semi-supervised learning: use case in bipolar disorder monitoring.
The formal recrutiment process of the team was already run in October 2021 enabling to recruit the two PhD student to work on the BIPOLAR project right from its beginning on January, 1st.

Just before the formal start of the project, the BIPOLAR team met in Poznań to get to know each other and spent some fun time together.
READ MORE